What Are Web Crawlers and How to Use Them Responsibly?

Web Crawlers Introduction
Let's start from the very beginning: what exactly are web crawlers? Simply put, web crawlers, also known as spiders or bots, are automated programs that systematically browse the internet, collecting data from websites. They play a crucial role in indexing information for search engines like Google, enabling users to find relevant information quickly. However, their application extends far beyond search engines, finding use in data analysis, market research, and even in personal projects. Despite their utility, the operation of web crawlers comes with significant responsibilities and limitations, governed by both legal and ethical standards.
Legal Boundaries
The internet, often perceived as a vast and open space, is not exempt from legal regulations. Laws governing the use of web crawlers are akin to school rules for students. For instance, during exams, teachers enforce strict no-cheating policies. Similarly, laws prohibit unauthorized access to websites. In the United States, unauthorized data scraping can violate the Computer Fraud and Abuse Act (CFAA), leading to serious legal repercussions. In China, the legal landscape is somewhat more ambiguous, but the primary principles remain:
- Do not access data without explicit permission.
- Do not disrupt the normal operation of websites.
A landmark case highlighting these principles occurred in April 2019, when the Shenzhen Intermediate People's Court handled China's first "crawler" software lawsuit. The defendant, the developer of the app "Chelaile," was found guilty of using crawler technology to extract large amounts of data from a competitor, resulting in a court order to pay 500,000 RMB in damages.
Ethical Boundaries
While legal boundaries set the minimum standards for behavior, ethical considerations often serve as our moral compass. Imagine you're at a buffet: while it's permissible to take food, it's unethical to hoard more than you can eat, resulting in waste. Similarly, web crawlers can collect data, but they must do so responsibly. Overloading a website with requests can cause disruptions, like causing chaos at the buffet.
Privacy is another critical ethical consideration. Collecting personal information without consent is like peeping through someone's window with binoculars – it's invasive and illegal. Therefore, ensure that the data your crawler collects is public, and legal, and doesn't infringe on user privacy.
Responsible Use of Web Crawlers
To use web crawlers responsibly within the confines of law and ethics, consider the following best practices:
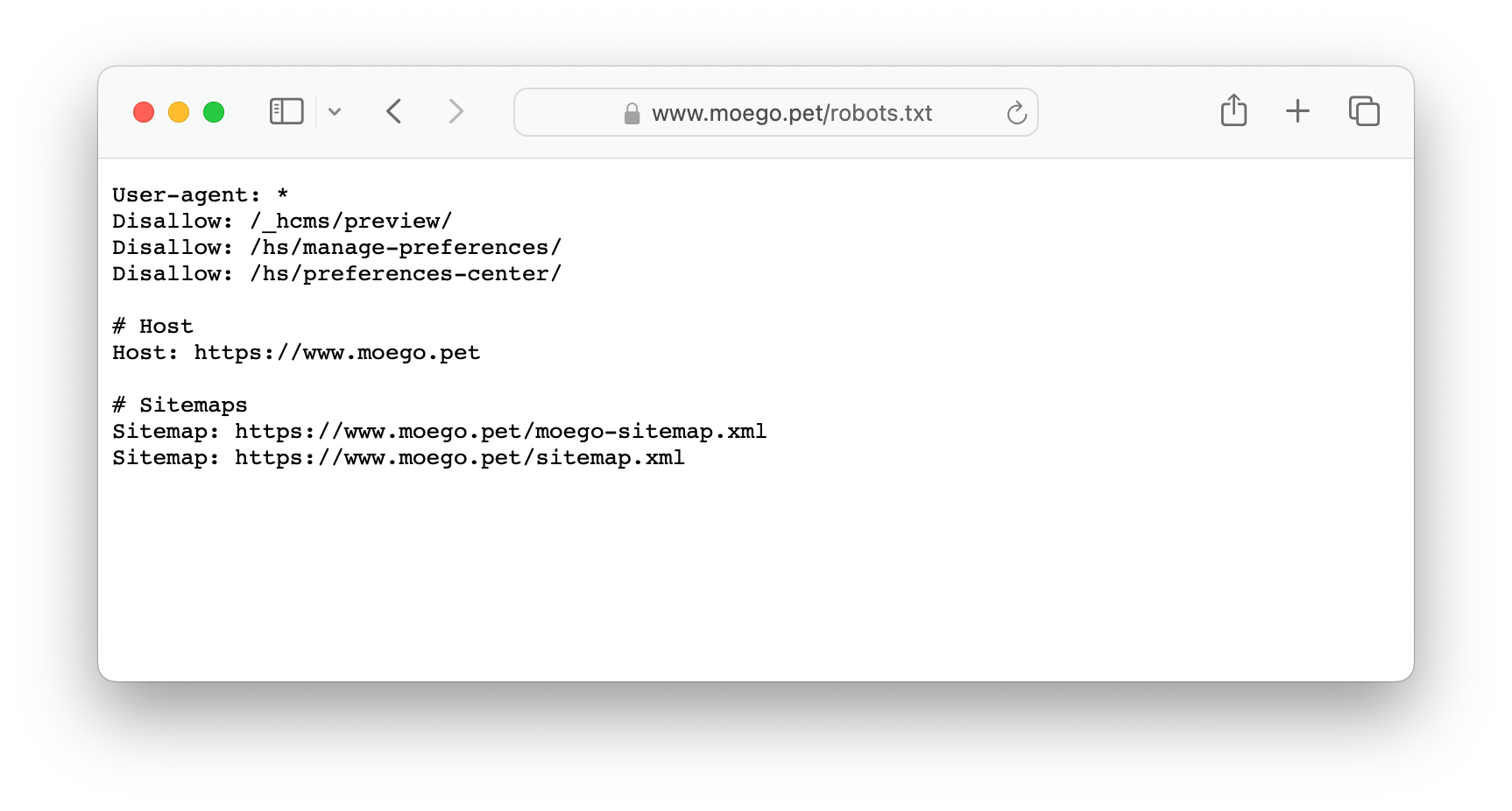
- Respect Website Policies: Always read the
robots.txtfile of websites. This file acts as a guide, specifying which parts of the site can be accessed by crawlers and which parts are off-limits. - Limit Access Frequency: Avoid overloading websites by incorporating appropriate intervals between requests, mimicking the behavior of a human user.
- Use Proxies and RPA Software: These tools can help distribute requests, reduce the risk of being blocked, and simulate normal user behavior.
- Opt for Legal Data Acquisition: Whenever possible, acquire data through legitimate means. Purchasing data through proper channels is often safer and more reliable than risking legal consequences by scraping it.
Defending Against Crawlers
The relationship between crawlers and anti-crawling measures is a dynamic, cat-and-mouse game, much like the interplay between swords and shields. For engineers, defending against unauthorized crawlers is crucial. Here are some effective strategies:
- Request Limiting and Denial: Implement rate limiting and access control measures to restrict the number of requests from a single source.
- Client Authentication: Utilize methods like IP blocking and user-agent filtering to identify and block suspicious activity.
- Text Obfuscation and Dynamic Rendering: Mix text with images and use CSS to obfuscate data, making it difficult for crawlers to parse.
- Captchas: From basic text challenges to sophisticated puzzles, captchas are a well-known defense mechanism.
For example, Qunar.com employs CSS shifts to display ticket prices, complicating data extraction. Captchas have evolved from simple text-based challenges to complex spatial reasoning puzzles that even humans find difficult, illustrating the intensifying battle against crawlers.
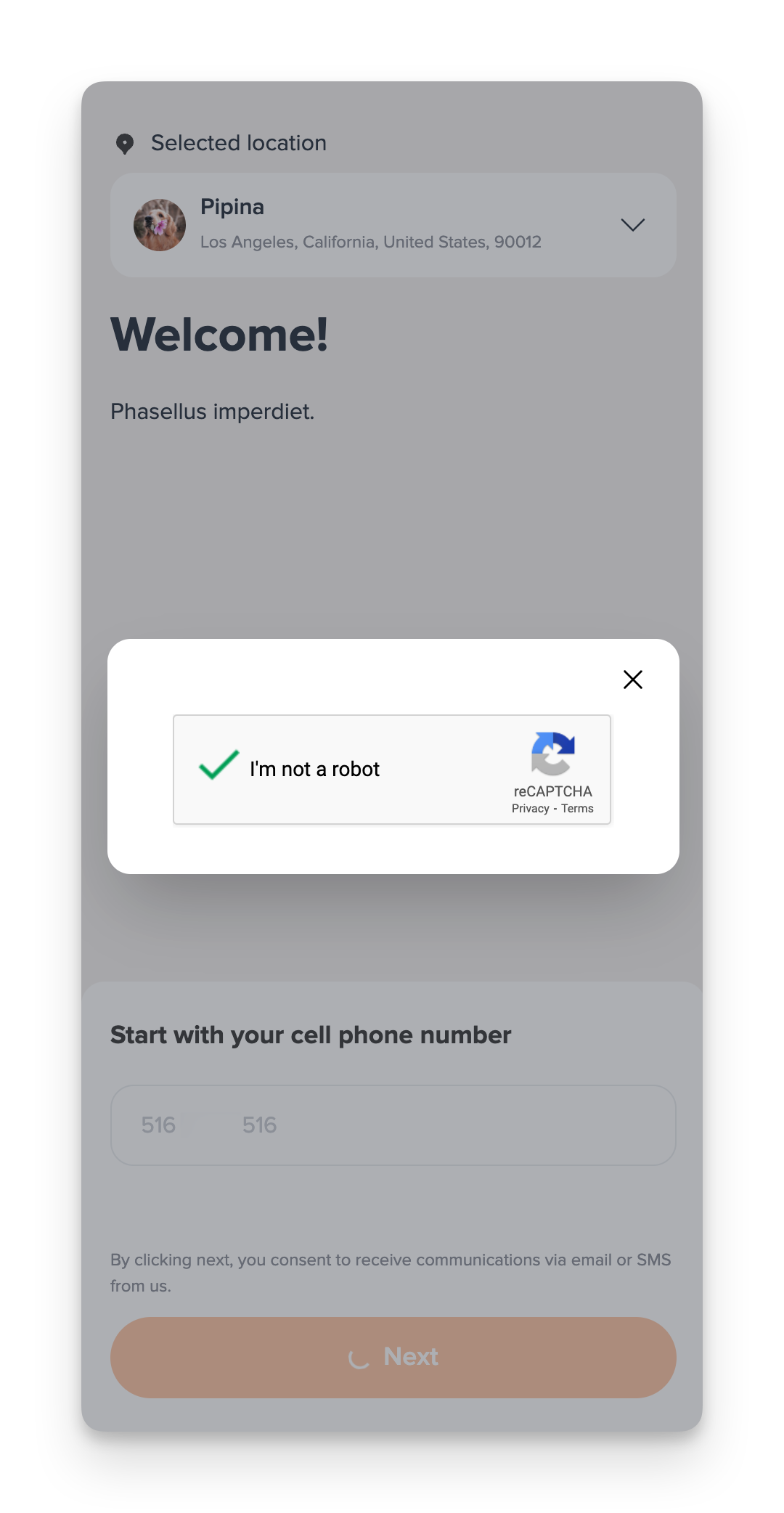
How MoeGo Defending Against Crawlers
To address the issue of malicious data scraping and unauthorized submissions, we have implemented Google reCAPTCHA on each user's MoeGo Online Booking website. This powerful tool helps us distinguish between human users and automated bots, thereby enhancing the security and integrity of the booking process. By deploying reCAPTCHA, we ensure that the data entered and accessed on our platforms is protected against unwanted intrusions, providing our users with a safer and more reliable online experience.
Summary
Web crawlers are a double-edged sword. When used correctly, they can provide valuable insights and streamline information gathering. However, when misused, they can lead to legal troubles and ethical dilemmas. As engineers at MoeGo, it is imperative to master the technology while adhering to legal and ethical standards. By fostering a strong sense of security and responsibility in our development practices, we can become conscientious digital citizens, leveraging the power of web crawlers to enhance our work without crossing boundaries.
Author Bio
Bob (bob@moego.pet), from MoeGo R&D.
References
- Web crawel definition
- What is a web crawler? | How web spiders work
- How to Crawl Responsibly: The Need for (Less) Speed
- Robots.txt definition
- Law and Ethics: The Boundaries of Web Crawlers
This work is licensed under a Creative Commons Attribution-NonCommercial-NoDerivatives 4.0 International License .